

QLoRA (Quantize Low-Rank Adapters) được xây dựng dựa trên thành công của LoRA (Low-Rank Adaptation) bằng cách giới thiệu lượng tử hóa để tối ưu hóa thêm quá trình tinh chỉnh các mô hình ngôn ngữ lớn (LLM). Cả hai kỹ thuật đều nhằm giải quyết các thách thức khi tinh chỉnh các mô hình LLM, thường dẫn đến các mô hình lớn, tốn nhiều bộ nhớ.
QLoRa giải quyết các thách thức về bộ nhớ và tính toán khi tinh chỉnh bằng cách sử dụng hai chiến lược chính:
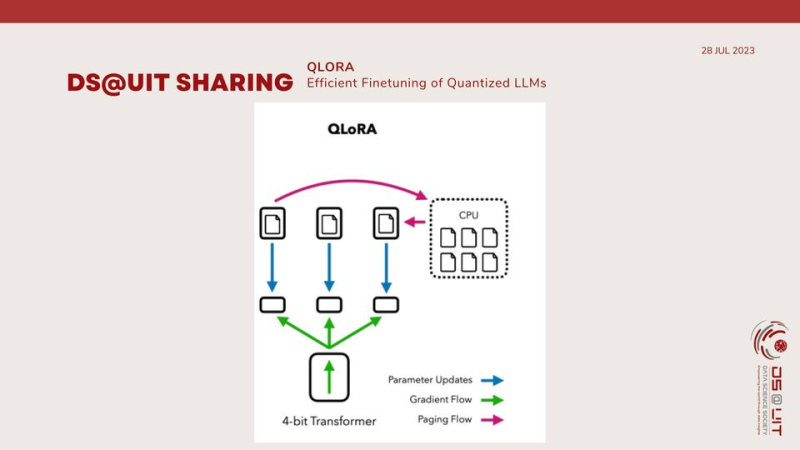
Lượng tử hóa: QLoRA lượng tử hóa trọng số của LLM thành độ chính xác bit thấp hơn, chẳng hạn như 4 hoặc 8 bit. Điều này làm giảm dung lượng bộ nhớ của mô hình mà không ảnh hưởng đáng kể đến hiệu suất của nó.
Thích ứng bậc thấp: Thay vì trực tiếp tinh chỉnh toàn bộ LLM, QLoRA giới thiệu các bộ điều hợp bậc thấp, là các ma trận nhỏ hơn thu thập các thay đổi quan trọng nhất đối với trọng số của LLM trong quá trình tinh chỉnh. Cách tiếp cận này làm giảm đáng kể số lượng tham số có thể đào tạo, dẫn đến việc tinh chỉnh nhanh hơn và hiệu quả hơn về bộ nhớ.
QLoRA mang lại một số lợi thế hơn so với các phương pháp tinh chỉnh truyền thống:
Giảm dung lượng bộ nhớ: Sự kết hợp lượng tử hóa và thích ứng bậc thấp của QLoRA làm giảm đáng kể dung lượng bộ nhớ của các mô hình được tinh chỉnh, làm cho chúng phù hợp hơn để triển khai trên các thiết bị có tài nguyên bộ nhớ hạn chế.
Tinh chỉnh nhanh hơn: Các kỹ thuật tối ưu hóa hiệu quả của QLoRA giúp tăng tốc đáng kể quá trình tinh chỉnh, cho phép phát triển và lặp lại mô hình nhanh hơn.
Hiệu suất tương đương: Các mô hình QLoRA duy trì hiệu suất tương đương với các mô hình được tinh chỉnh hoàn toàn, cho thấy hiệu quả của nó trong việc bảo toàn khả năng của LLM gốc.
Trực giao với các phương pháp khác: QLoRA là trực giao với nhiều phương pháp hiệu quả về tham số khác, cho phép tối ưu hóa và tùy chỉnh hơn nữa.
Mọi thông tin chi tiết xem tại:
Hạ Băng - Cộng tác viên Truyền thông trường bet365 betting



, nhiệm kỳ 2020 - 2025")


